


 A more unfortunate “bug” or quirk is Llama-3’s base (not instruct) model has untrained tokens, namely <|reserved_special_token_{0->250}|>
A more unfortunate “bug” or quirk is Llama-3’s base (not instruct) model has untrained tokens, namely <|reserved_special_token_{0->250}|>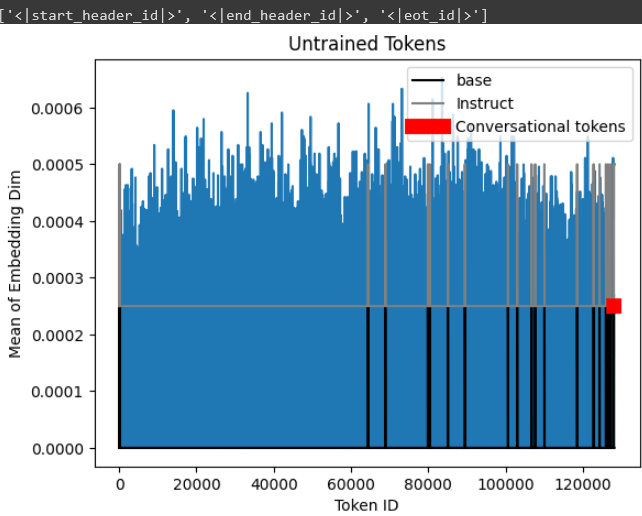 Essentially if one uses these untrained tokens (like using the instruct template for the base model), then gradients will be NaN. As first noticed by Geronimo, one has to simply set these untrained tokens to be the mean vector.
Essentially if one uses these untrained tokens (like using the instruct template for the base model), then gradients will be NaN. As first noticed by Geronimo, one has to simply set these untrained tokens to be the mean vector.
